*This article was first published by Edward Dixon, Alex Ott, and Damilare Fagbemi on Medium.
Machine Learning As A Service (MLaaS) is the latest variation in the trend of offering software services via the cloud. From the software vendor’s perspective, a significant advantage of the cloud model of software delivery, is the prevention of software piracy. Software delivery via the cloud eliminates the need to deliver software binaries or code directly to end users. This usually means that vendors need not be concerned with their software being reverse engineered, cracked, or re-purposed — except the cloud hosting environment is hacked, but that is an entirely different story. However, as we will show, machine learning comes with new vulnerabilities as well as new capabilities that make it relatively cheap and easy to reverse-engineer or replicate functionality, even without access to the source code, binaries, or the machine learning model’s parameters. d
Stealing Machine Learning Services for Fun and Profit
Reverse-engineering is probably as old as technology itself. In software, it involves the process of analyzing software code or binaries for a variety of reasons such as the removal of copy protection, circumvention of access restrictions, piracy via intellectual property theft etc. Software vendors use techniques like code obfuscation, which is the deliberate creation of code that is difficult for humans to understand, in order to frustrate reverse engineering. This achieves mixed success, since clever people with good tools can pick anything apart. Usually, the amount of effort applied by reverse engineers will be proportional to the amount of perceived value. Popular games or applications are broken in hours or days. It turns out that in machine learning, reverse-engineering — or at least, using a competitor’s product to guide the creation of a functional equivalent — can be fast, easy and cheap.
Taking a concrete example, Amazon Web Service’s Rekognition service can analyse images in lots of ways. For instance, it can be used to detect or recognize faces. It also does simpler things like measuring image quality (brightness and sharpness) via machine learning. Suppose we want to offer a competing service — how could we train a similar model? How would we create a suitable training set? Creating a labeled dataset is often one of the most time-consuming and expensive parts of a machine learning project.
One simple way would be to feed (unlabelled) images to the AWS Rekognition service we want to replicate and record the output or label for each image. The nice thing about having your data labelled by another model rather than humans (apart from the much lower cost of labelling) is that models output well conditioned class probabilities: instead of just saying “sharp” or “not sharp”, we get a number that quantifies just how sure the model is about whether this image is sharp or not. It turns out that models can learn a lot faster from data that is labelled like this than they can from less informative binary labels. This approach to machine learning is called student-teacher training (or, sometimes, “knowledge distillation”), and is typically used to
produce a smaller, less computationally expensive model from one or more larger models, although recent work has also demonstrated the potential for a “student” model to outperform its “teacher”.
How easily can we apply this in practice? We fed about 50,000 images to AWS Rekognition, to get our labels — this cost about $50 ($1 per 1,000). We then used transfer learning to train a CNN architecture called “Xception” to model the AWS labels as a regression task — i.e., given an image and a target output of “97% sharp”, figure out a rule that gives approximately the same output. There isn’t much engineering effort involved — just a few dozen lines of Python code that would require minimal changes to reverse-engineer other similar services.
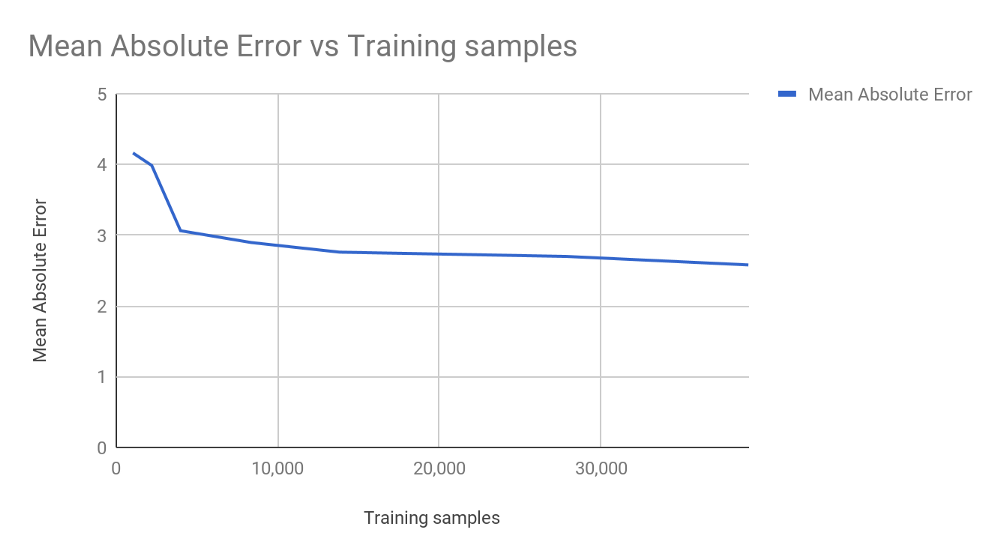
As you can see, results were already quite good when we trained on only ¼ of the labelled data; we could’ve spent just $10 and got a reasonable result. All that remains is to deploy our trained model and start serving predictions. Turns out we could do that for about $0.002 per 1,000 to undercut AWS (who charge $1 for a thousand predictions — a profit margin of 99.8%!). Given the minimal costs of duplicating a model (a few dozen lines of code, minutes of model training time), it is clear that the machine learning equivalent of reverse-engineering is far cheaper and more tempting than doing similar things with traditional software.
For example, we found it trivial to train our own ResNet50 model to locate facial keypoints.

A ResNet50 student model learns to locate the “nose” keypoint in a few epochs
Potential Mitigations
Service providers may try to mitigate problem by different means:
- Cap on the amount of data classified by “new users”, comparing to limits provided to “established users”; however, given, the very small amounts of labelled data the “student” model required, this could create even worse problems — even $10 of data classification was enough for us to train an effective model. Does anyone really want to cap sales to a given customer below $10?
- Limiting amount & precision of information provided by service — instead of probabilities, bin responses — “highly likely”, “probable”, etc. We experimented with quantizing the labels available to our student model, and binning does slow (but not stop) model learning.
- Instead of giving users a model’s output, build an application that uses the model output to do something for the user.
- EULA terms limiting the uses to which customers can put the model’s output
Not Actually Stealing
Unless your terms of service actually forbid it, a customer who duplicates your model and serves up a (much cheaper!) version probably hasn’t broken any laws. Reverse engineering machine learning is likely to remain a “fact of life” to be factored into the planning and design of machine learning-based products.



